PREDIKSI PENYAKIT KANKER DENGAN
MODEL DECISION TREE (POHON KEPUTUSAN)
Herryawan Pujiharsono1, Dwi Kurniawan2, Rio Irsyad3
1,2,3 Program Studi Teknik Elektro, Jurusan Teknik, Fakultas Sains dan Teknik, Universitas Jenderal Soedirman
Jl.Kampus No.1 Grendeng Purwokerto Utara
Email : i1a006009@yahoo.co.id1, dias.no1@gmail.com2, link_eyes@yahoo.com3
ABSTRAK
Penentuan seseorang menderita cancer atau tidak dilakukan dengan beberapa tahap uji laboratorium. Pengambilan keputusan dilakukan dengen berbagai metode, salah satunya dengan menggunakan model decision tree (pohon keputusan). Model ini merupakan metode yang berusaha menemukan fungsi-fungsi pendekatanyang bernilai diskrit dan tahan terhadap data-data yang terdapat kesalahan.Pengambilan keputusan cancer atau bukan dilakukan dengan cara menuliskan pohon keputusan kedalam bentuk first order logic yang merupakan ekspresi sederhana dari operasi-operasi disjunction dan conjunction.
Kata Kunci: Decision tree, Prediksi, Cancer.
1 .PENDAHULUAN
Cancer disebut juga sebagai tumor ganas karena perkembanganya sangat cepat dan tidak terkendali. Cancer dapat dengan mudah menyebar ke organ-organ tubuh lainya dan menyebabkan kematian.
Umumnya,cancer diketahui setelah setadium lanjut karena gejala cancer sendiri tidak nyata dan mirip dengan penyakit lain yang tidak ganas sehingga penderita cancer yang datang memeriksakan diri ke klinik kebanyakan telah menderita cancer pada setadium lanjut.Oleh karena itu pengobatanya menjadi sangat sulit,apalagi bila sel cancer sudah menyebar.
Karena sifat dari gejala cancer yang sulit di identifikasi,maka dilakukan uji laboratorium bertahap yang kemudian sering disebut sebagai uji saring.Pemeriksaan ini juga dimaksudkan untuk deteksi dini penyakit cancer.
Yang menjadi permasalahan adalah :
- Diperlukan beberapa uji laboratorium untuk memastikan seseorang penderita cancer atau bukan.
- Diperlukan data sample yang banyak sebagai data pembanding.
- Dari data uji laboratorium yang didapat,diperlukan metode pengambilan keputusan yang baik sehingga kesalahan dalam nenentukan si pasien terkena cancer atau tidak menjadi lebih kecil.
Sehingga,berbagai metode penggalian informasi dari data sample yang ada mulai bermunculan.Salah satu metode yang dapat digunakan adalah decision tree.
2 METODE DAN IMPLEMENTASI
Terdapat banyak sekali metode yang terdapat dalam teknik penggalian data dengan berbagai variasinya yang telah diusulkan dan diimplementasikan. Beberapa contoh metode yang sering digunakan adalah decision tree, jaringan syaraf tiruan, regresi bertingkat, dan algoritma genetika.
Untuk kasus kali ini, digunakan metode decisión tree karena target hanya berupa data biner (0 dan 1) sehingga optimal dalam melakukan klasifikasi.
2.1 Entropy
Entropy merupakan suatu parameter untuk mengukur heterogenitas atau keberagaman dari suatu kumpulan sampel data. Jika kumpulan sampel data tersebut semakin heterogen, maka nilai entropy-nya semakin besar. Secara matematis, entropy dirumuskan sebagai berikut :

Dimana c adalah jumlah nilai yang ada pada atribut target. Sedangkan Pi menyatakan jumlah sampel untuk kelas i.
2.2 Information Gain
Setelah kita mendapatkan nilai entropy untuk suatu kumpulan sampel data, maka kita dapat mengukur efektivitas suatu atribut dalam mengklasifikasikan data. Ukuran efektivitas ini disebut sebagai information gain. Secara matematis information gain dari suatu atribut A dapat dituliskan sebagai berikut : di mana :
di mana :
 di mana :
di mana :
A : atribut
V : menyatakan suatu nilai yang mungkin untuk atribut A Values(A) : himpunan nilai-nilai yang mungkin untuk atribut A
|Sv| : jumlah sampel untuk nilai v
|S| : jumlah seluruh sampel data
Entropy(Sv) : entropy untuk sampel sampel yang
memiliki nilai v
3 SKENARIO UJI COBA
Data yang digunakan sebagai prediktor adalah data usia dan empat buah hasil uji lab untuk pasien pada sebuah klinik ’X’ dengan dimana tipe data hasil lab terdiri dari dua buah tipe ordinal, yaitu tipe data yang bersifat urutan atau tingkatan dan tipe nominal, yaitu tipe data bersifat penggambaran keadaan dan tidak mempunyai urutan. Dari empat buah tipe tersebut, data yang bertipe ordinal adalah hasil uji lab pertama dan keempat, sedangkan tipe data yang bersifat nominal adalah hasil uji lab kedua dan ketiga. Sedangkan data yang digunakan sebagai target adalah cancer.
Banyaknya data yang digunakan sebagai data training adalah 861 buah dengan 395 buah data memiliki nilai cancer sama dengan 1 dan 466 buah data memiliki cancer sama dengan 0 dimana nilai 0 dan 1 ini muncul pada data usia dan hasil uji lab yang berbeda dan bervariatif. Bahkan ada beberapa data usia dan hasil uji lab yang sama tetapi menghasilkan kesimpulan yang berbeda. Untuk mendapatkan hasil akurasi yang cukup akurat digunakan teknik decision tree dimana data diolah secara bertingkat dengan berdasarkan tingkat kekuatan informasi (information gain) antara prediktor dengan target.
Dari kelima prediktor, yaitu usia, hasil uji lab pertama, kedua, ketiga, dan keempat, didapat hubungan antara prediktor dengan target bahwa yang memiliki tingkat kekuatan data paling besar adalah hasil pertama. Oleh karena itu, hasil uji lab pertama menjadi root teratas dalam decision tree. Dari hasil uji lab pertama ini diketahui bahwa jika nilai hasil uji lab adalah lebih besar atau sama dengan 5 maka target akan bernilai 1 dengan misclassification sebesar 12,88 % dari 326 data sampel yang memiliki nilai hasil uji lab pertama lebih besar atau sama dengan 5. Sedangkan jika hasil uji lab pertama kurang dari 5 sebanyak 535 data sampel akan dilakukan analisis selanjutnya untuk menentukan root kedua.
Tingkat kekuatan informasi yang selanjutnya berpengaruh jika hasil uji lab pertama adalah hasil uji lab kedua. Jika nilai hasil uji lab kedua bernilai 1,2, dan 3 maka nilai target adalah 0 dengan misclassification sebesar 11,9 % dari 420 data sampel. Untuk hasil uji lab kedua yang bernilai 4 dilakukan proses analisis selanjutnya untuk root ketiga.
Selanjutnya, tingkat kekuatan informasi yang berpengaruh adalah usia. Karena usia merupakan data yang beragam nilainya dari 18 sampai 96 maka untuk mendapatkan tingkat keakurasian data, usia mendapat dua macam perlakuan, yaitu tanpa pengelompokan dan dengan pengelompokan yang memiliki rentang 5 tahun.
Sebenarnya hasil uji lab ketiga dan keempat juga berpangaruh untuk analisis selanjutnya, tetapi setelah melalui hasil pemotongan atau pruning, hasil uji lab ketiga dan keempat ini dapat dihilangkan sehingga didapatkan tingkat keakurasian yang cukup besar.
Tingkat keakurasian ini diukur dengan memasukkan kembali persamaan yang diperoleh dari aturan decision tree ke dalam data training yang sebelumnya digunakan untuk mencari aturan yang menghubungkan antara prediktor dengan target.
4 HASIL UJI COBA
Hasil dari analisis penggalian data dengan menggunakan decision tree didapatkan bentuk pohon keputusan sebagai berikut:
· Tanpa pengelompokan usia
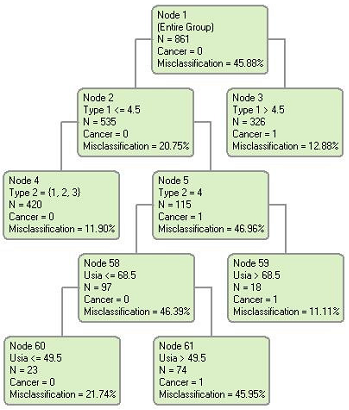
Gambar 1. Pohon keputusan tanpa pengelompokan usia
Aturan yang diperoleh dari pohon keputusan pada Gambar 1 adalah sebagai berikut:
o (tipe1 > 4,5) => cancer = 1
o (tipe1 ≤ 4,5) Λ (tipe2 = {1,2,3}) => cancer = 0
o (tipe1 ≤ 4,5) Λ (tipe2 = 4) Λ (usia ≥ 49,5) => cancer = 1
o (tipe1 ≤ 4,5) Λ (tipe2 =4) Λ (usia ≤ 49,5) => cancer = 0
· Dengan pengelompokan usia rentang 5 tahun
Pengelompokan usia dengan rentang 5 tahun adalah sebagai berikut:
o Level usia 0 : 15 – 20
o Level usia 1 : 21 – 25
o Level usia 2 : 26 – 30
o Level usia 3 : 31 – 35
o Level usia 4 : 36 – 40
o Level usia 5 : 41 – 45
o Level usia 6 : 46 – 50
o Level usia 7 : 51 – 55
o Level usia 8 : 56 – 60
o Level usia 9 : 61 – 65
o Level usia 10 : 66 – 70
o Level usia 11 : 71 – 75
o Level usia 12 : 76 – 80
o Level usia 13 : 81 – 85
o Level usia 14 : 86 – 90
o Level usia 15 : 91 – 95
o Level usia 16 : 96 – 100

Gambar 2. Pohon keputusan dengan pengelompokan usia
Aturan yang berlaku dari pohon keputusan pada Gambar 2 adalah sebagai berikut:
o (tipe1 > 4,5) => cancer = 1
o (tipe1 ≤ 4,5) Λ (tipe2 = {1,2,3}) => cancer = 0
o (tipe1 ≤ 4,5) Λ (tipe2 = 4) Λ (level usia = {3,4,5,6,8}) => cancer = 0
o (tipe1 ≤ 4,5) Λ (tipe2 =4) Λ (level usia = {2,7,9,10,11,12,14}) => cancer = 1
Tingkat keakurasian yang diperoleh dari aturan kedua pohon keputusan tersebut adalah 84,4 % (729 data sesuai dengan nilai target) untuk metode tanpa pengelompokan usia dan 84,7% (730 data sesuai dengan nilai target) untuk metode dengan pengelompokan usia rentang 5 tahun.
Berdasarkan tingkat keakurasian data tersebut, maka aturan pohon keputusan yang digunakan adalah aturan dengan pengelompokan usia rentang 5 tahun.
5 KESIMPULAN
Dari hasil di atas, metode decision tree dapat digunakan untuk memprediksi cancer berdasarkan data usia dan uji laboratorium. Untuk meningkatkan tingkat keakurasian, data usia dikelompokkan ke dalam level usia dengan rentang 5 tahun. Aturan yang diperoleh dari proses decision tree menggunakan first order logic (aturan logika) dan untuk mengoptimalkan atau meminimalisir banyaknya root dalam pohon keputusan sehingga aturan logika menjadi lebih sederhana dapat dilakukan dengan cara pemotongan atau pruning.
6 DAFTAR PUSTAKA
[1] Gardner, William A. 1986. Introduction to Random Process With Applications to Signals and Systems. New York : Macmillan Inc.
[2] Siang, J.J. 2009. Jaringan Syaraf Tiruan dan Pemrogramannya Menggunakan Matlab. Yogyakarta : Andi Offset.
[3] Supranto, J. 2001. Statistik: Teori dan Aplikasi. Jakarta : Erlangga.
[4] Suyanto, S.T., M.Sc. 2007. Artificial Intellegence: Searching, Reasoning, Planning, dan Learning. Bandung : InformatikaContoh lain mengenai Decision tree learning ada di sini
wah, hebat boy.
BalasHapushasilnya udah cukup mantap yah.
belajar lagi ah. semangat boy!
<@skilef >
BalasHapusThx semangatnya bro...
moga sukses pak ST
Contoh lain dapat didownload di :
BalasHapushttp://www.megaupload.com/?d=NKRQ93WY